Introduction
On the last day of 2023, Vitalik shared Ethereum’s roadmap for 2023 on Twitter, summarizing the progress of Ethereum over the year. The roadmap section “The Verge” described how Ethereum’s technology could verify blockchain states more simply and efficiently. A core concept mentioned there is the Verkle Trees. So, what are Verkle Trees, why Ethereum needs it, and how do Verkle Trees solve problems? The goal of this article is to answer these questions for readers without delving too deeply into cryptography and mathematics, helping those with some understanding of Ethereum quickly grasp the concept of Verkle Trees.
Verifiable Query
Verifiable query technology is widely researched in the field of traditional databases, primarily used to solve trust issues with external databases. In many scenarios, data owners might choose not to store data themselves but instead entrust their database needs to a third party to provide database services (such as cloud databases). However, because third parties are not always trustworthy, the credibility of the query results they return to users is difficult to guarantee. The current verifiable query solutions for traditional databases mainly fall into two categories: those based on ADS (Authenticated Data Structures) and those based on verifiable computation.
ADS is a verifiable query technique extensively used in traditional databases, mostly built upon structures like Merkle Trees or similar accumulative structures. With the evolution of cryptographic tools, many researchers have gradually begun to explore the use of verifiable computation techniques to address issues with untrustworthy queries. Some verifiable computation schemes based on Zero-Knowledge Proof protocols, such as SNARKs, can indirectly support verifiable queries for external databases. These schemes support a wide variety of query types and generate less verification information, but they have higher computational overheads.
Currently, Ethereum uses Merkle Trees to implement verifiable queries, and the Verkle Tree technology is also based on Merkle Tree technology. Therefore, let’s first introduce Merkle Trees to help readers understand the role of verifiable queries using them as an example.
Merkle Trees
Definition and Characteristics of Merkle Trees
Merkle Trees are a tree-like structure commonly used in cryptography, suitable for solving data integrity issues. Below is a typical Merkle Tree structure: the leaf nodes represent the original data or their hash values, and each non-leaf (internal) node contains the combined hash of its child nodes.
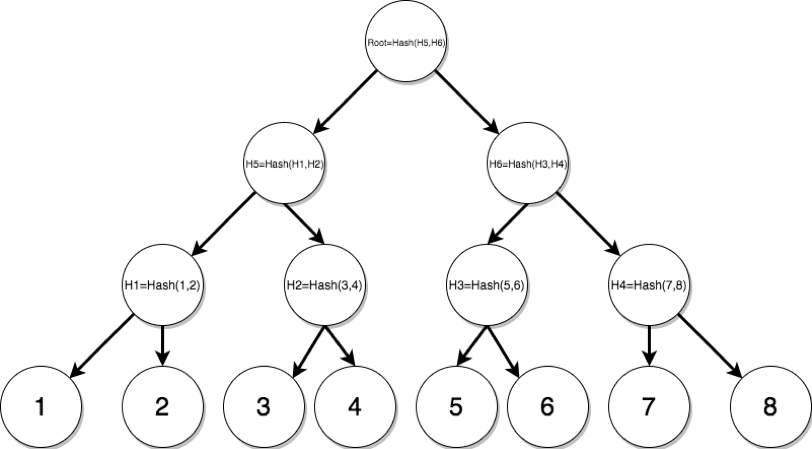
Merkle Trees have two important characteristics:
- Tamper-Resistance: Merkle Trees are typically constructed using collision-resistant hash functions, making it computationally infeasible to find two different messages that produce the same hash value. From the structure of a Merkle Tree, it is apparent that any modification to transaction data within a leaf node will result in a change to the root hash of the tree.
- Efficient Integrity Verification of Large Datasets: Verifiers only need to store the root hash of the Merkle Tree to verify the integrity of any data. This is achieved without transmitting the complete data set, but rather by using sibling nodes along the path from the leaf to the root, known as a Merkle Path. These sibling nodes can be used to reconstruct the root hash for verification purposes.
How to construct a Merkle proof?
In a common verifiable query scenario, there is a prover and a verifier. The prover needs to generate a proof and send it to the verifier. Corresponding to the Ethereum network, a typical application scenario is where a light node (a client that only stores block headers) queries transaction data from a full node or an archive node (clients with all data) and obtains a Merkle proof to locally verify whether the query result is correct.
The Merkle proof consists of the following three parts:
- The root hash of the Merkle tree for the complete dataset.
- The data block whose integrity needs to be proven.
- The Merkle Path, which includes the values of all sibling nodes on the path from the leaf node to the root node.
Among these, the root hash of the Merkle tree needs to be sent to the verifier in advance through a trustworthy means, and the verifier must trust this value. In Ethereum, the trustworthiness of block data is ensured by the consensus algorithm, and the root hash of the Merkle tree is contained within the block header.
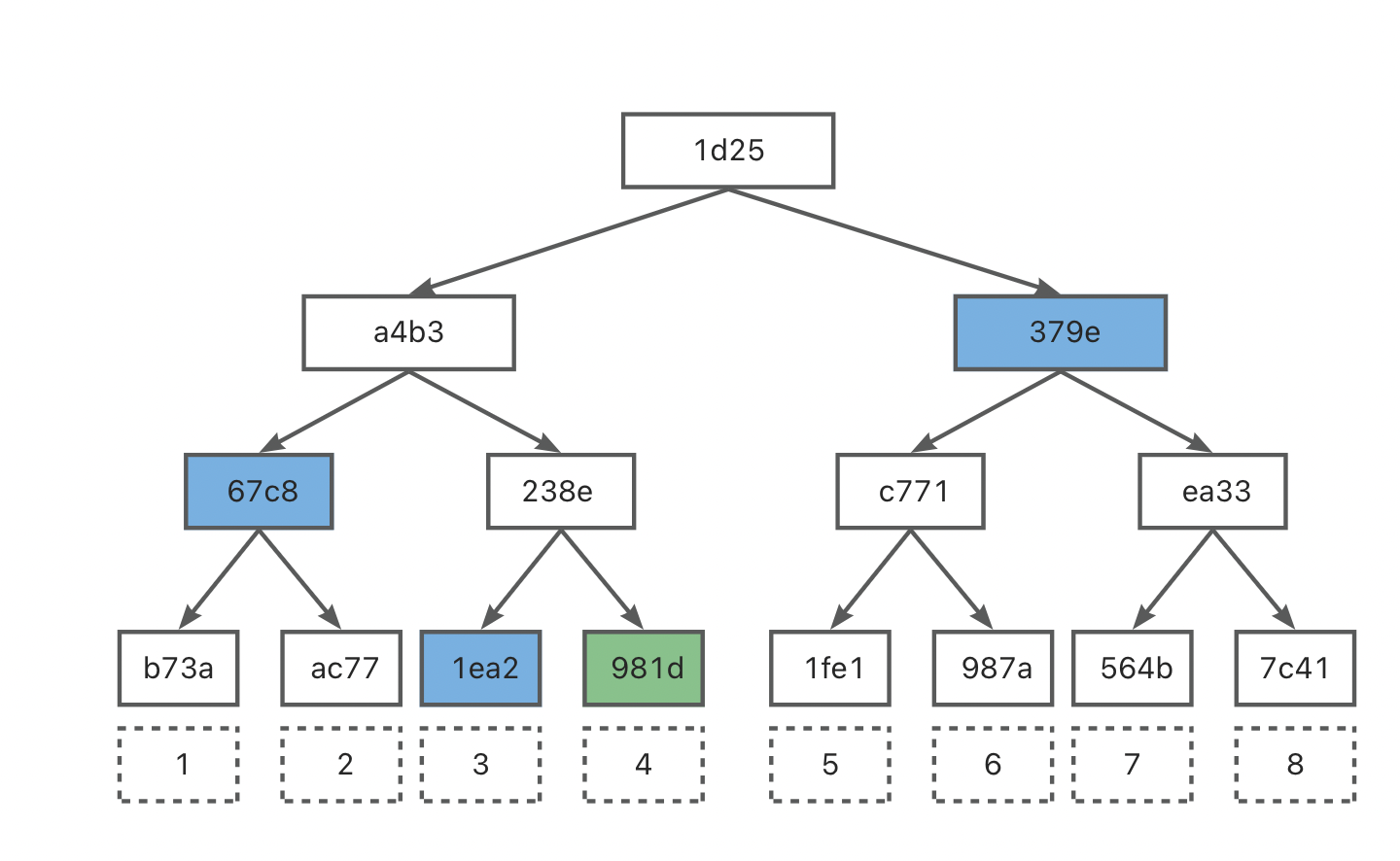
Below is a specific example: when the prover needs to prove to the verifier that “4” is a data block existing in the dataset, and the verifier holds the trusted root hash “1d25” of the complete dataset’s Merkle tree, then the prover only needs to provide all the data marked in blue. Assuming there are n pieces of data in the set, at most $log_2(n)$ hash computations are needed to verify the correctness of any data block.
Ethereum’s light nodes synchronize only the block headers, which contain the roots of Merkle Trees for various sets of data (state tree, transaction tree, receipt tree). When a light node queries a full node for a particular leaf node’s data in the tree, the full node returns the original data along with the corresponding Merkle proof path. This allows the light node to trust the correctness of the query result.
Variants of Merkle Trees
Building upon the foundation of Merkle Trees, they can be combined and modified with other data structures to achieve new characteristics based on different objectives. To cater to various verifiable query scenarios, Merkle Trees can be extended to various indexed data structures, such as Merkle-B Trees (MBT). For efficient execution of operations like insertion, deletion, and querying, the Ethereum team proposed the Merkle Patricia Tree (MPT).
Merkle-B Tree
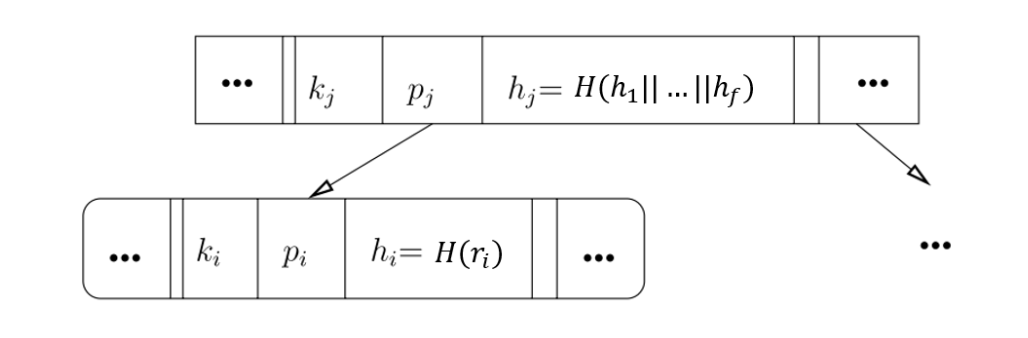
The Merkle-B Tree (MBT) is mainly used for handling verifiable range queries. Let 𝑓 be the fan-out of the MBT (the number of child nodes for each node). Based on the B+ tree structure, each internal node of the MBT, besides storing 𝑓 - 1 index keys and pointers to 𝑓 child nodes, also maintains the hash values of all its child nodes in a summarized form. Below is a representation of the structure of leaf nodes and internal nodes in an MBT.
When it is necessary to prove that the data returned from a certain range query conforms to the specified range, the server that computes the Verification Object (VO) must first perform two top-down search operations to find the left and right boundaries. It must also return all the data within this boundary as well as the hashes of all the branches needed to construct the path to the root hash.
The drawback of this data structure is that the returned VO can only prove that the query results are within the requested query range, but it cannot prove that the returned results are complete.
Merkle Patricia Tree
If a naive Merkle Tree is used to provide verifiable queries, the time-consuming process of regenerating the Merkle tree root after each data insertion or deletion can become significant. In addition, it necessitates the maintenance of additional data search trees for storage. The Merkle Patricia Tree (MPT) combines attributes of a Radix Tree (compact prefix tree) and a Merkle Tree, allowing it to perform insertions, deletions, and queries in O(log(N)) time. For a complete understanding of MPT, readers can refer to detailed technical articles on the subject. This article will only introduce some basic definitions and provide examples to help readers quickly understand MPT.
Ethereum’s underlying structure employs a key-value database for storage, meaning data is stored in the form of key-value pairs. The MPT is also decomposed into key-value pairs for storage. We define the logical structure of MPT nodes as follows:
- index
- path
- data

In the context of the Merkle Patricia Tree (MPT), the “index” refers to the key of a key-value pair, while the “path” combined with the “data” constitutes the value of the key-value pair. The index actually stores the hash of the Merkle tree node, and the path corresponds to the path string used in the prefix tree to find the target node. Ethereum uses hexadecimal strings as path strings, and therefore the width of the MPT is 16. The data is the target data corresponding to the path.
Below is an example of an MPT that has been optimized with compressed prefixes, storing the following key-value pair data:
1 | { |

To find the data “duck” using the path “395,” you would start at the root hash and proceed through hashA, hashC, and hashD to ultimately reach the target data. Here’s a step-by-step guide:
- Root Hash: This is the entry point of the Merkle Patricia Tree (MPT), and you would use it to find the first node.
- hashA: Based on the root hash, you would retrieve the node or content identified by hashA. Since the path is “395,” you’re looking for the part of the tree that will lead you to “3”.
- hashC: After accessing the content of hashA, you continue to follow the path. The next segment, “9”, leads you to hashC.
- hashD: Finally, continuing down the path, the last segment “5” points you to hashD, which contains the value “duck”.
At each step in the path, the MPT leverages the properties of both the Radix Tree, for finding the correct path based on the key, and the Merkle Tree, for ensuring the integrity of the data through hash links. The “paths” in the tree are typically represented with a hexadecimal encoding, which corresponds with the tree’s branching factor of 16. Each node in the path includes enough hash pointers (to children nodes) and values to verify the integrity of the data and to navigate through the tree.
Please note that in a real MPT, the paths and the data would be encoded and stored in a specific format, and additional types of nodes (such as extension nodes and leaf nodes) help to optimize the structure for efficiency in different scenarios.
Vector Commitment
Commitment[1] schemes are cryptographic primitives that ensure data privacy and integrity. They are widely used in scenarios such as zero-knowledge proofs and secure multiparty computation. A basic commitment scheme is divided into two stages: the commit phase and the reveal (or open) phase.
- Commit Phase: In this phase, the committer uses a cryptographic algorithm to bind a message to a commitment value and sends this commitment value to the recipient. At this stage, the commitment possesses two properties: hiding and binding. Hiding ensures that the content of the committed message is unknown to everyone except the committer. Binding ensures that once a commitment has been made, it cannot be altered by anybody, including the committer.
- Reveal (Open) Phase: During this phase, the committer can prove to the recipient that the commitment value they received is a valid commitment to the original message. The commitment has the property of correctness, meaning that if both the committer and the recipient follow the protocol correctly, the recipient will be convinced that the commitment value they received during the commit phase is a valid commitment to the original message.
Vector Commitment is a special type of commitment scheme proposed by Catalano et al. [2] that allows a committer to make a commitment to an ordered set of messages 𝑚 = ⟨𝑚1 , 𝑚2 , …, 𝑚𝑞 ⟩ and to reveal (open) at any specified position to prove that message 𝑚𝑖 is the ith committed message. In vector commitments, binding means that no one can open the same position to reveal different messages.
A vector commitment scheme typically consists of the following algorithms:
$Gen(1^λ,q)→pp$ The key generation algorithm, upon input of a security parameter λ and vector length;
$Commit(pp,<\it m_1,m_2,...,m_q\gt)→(C,aux)$, Commitment algorithm, upon input of public parameters and a vector composed of q messages, outputs a commitment C and auxiliary information aux;
$Open(pp,i,m_i,C,aux)→π$, Proof generation algorithm, given public parameters pp and relevant information, generates a proof π through the commitment C and auxiliary information aux, if and only if $𝑚_𝑖$ is the ith message in the message vector;
$Verify(pp,C,i,m,π)→{accept \ or\ reject}$, Verification algorithm, given public parameters pp, commitment C, message m, index i, and proof π, outputs accept if and only if message m is the ith message in the original vector and π passes verification; otherwise, it outputs reject.
Verkle Trees
Definition and Characteristics of Verkle Trees
Definition:Verkle Trees = Vector Commitments + Merkle Trees。
Please note:Vitalik Buterin, the co-founder of Ethereum, has a blog post specifically dedicated to introducing Verkle trees. This chapter adds some background and mathematical knowledge based on his blog. Some of the data and illustrations in the following text are derived from his blog.
Verkle Trees (VTs) are characterized by providing smaller proofs compared to Merkle Trees. For data on the scale of billions of entries, a Merkle tree might generate proofs around 1KB in size, whereas Verkle tree proofs can be less than 150 bytes. This compact proof size is advantageous for implementing “stateless clients“.
The structure of a Verkle tree is somewhat similar to that of the Merkle Patricia Tree (MPT). Here’s an example of its structure. The nodes of a Verkle tree can be: (i) Empty, (ii) Leaf nodes containing a key and its corresponding value, or (iii) Internal nodes with a fixed number of child nodes. This number of children is also referred to as the “width” of the tree.
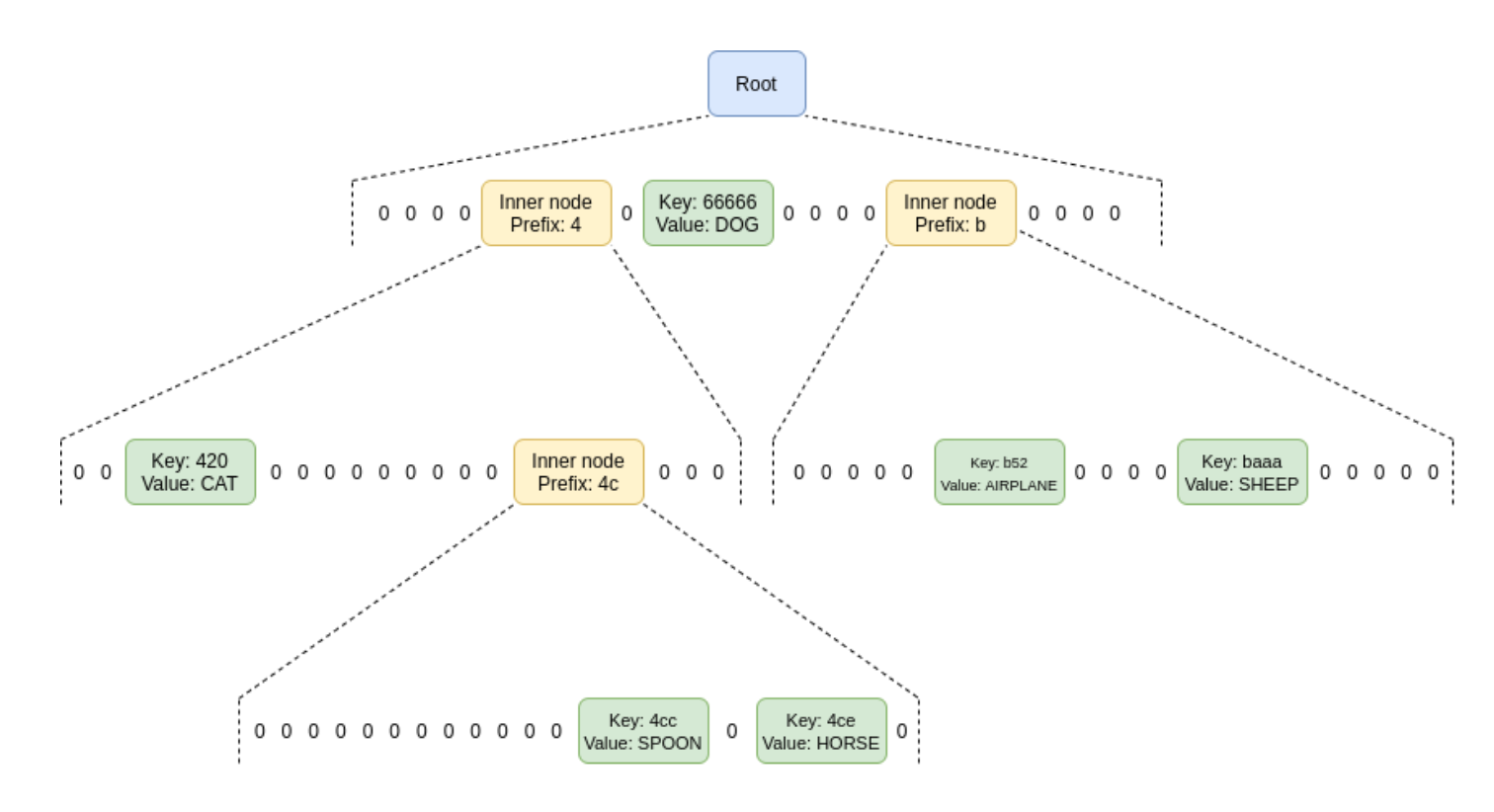
The difference between VT (Verkle Trees) and MPT (Merkle Patricia Trees) lies primarily in how the tree width (or fan-out, which refers to the number of child nodes a node in the tree has) affects their efficiency. In the case of MPT, if the width is larger, it tends to be less efficient because a greater width means more sibling nodes, which could lead to longer update times for the MPT and larger proof sizes. Conversely, for VT, a wider tree width results in smaller proofs. The only restriction is that if the width is too high, the time it takes to generate a proof can become longer.
In Ethereum’s design proposals for VTs, a width of 256 is suggested, which is significantly larger than the current 16 for MPT. Such a large width is feasible in VTs because of the use of advanced cryptographic techniques, such as vector commitments, that enable compact proofs regardless of the tree’s width. This compression technique allows Verkle Trees to scale more efficiently in terms of proof size. The subsequent text will explain the features mentioned above in more detail.
Commitment and Proof of Verkle Trees
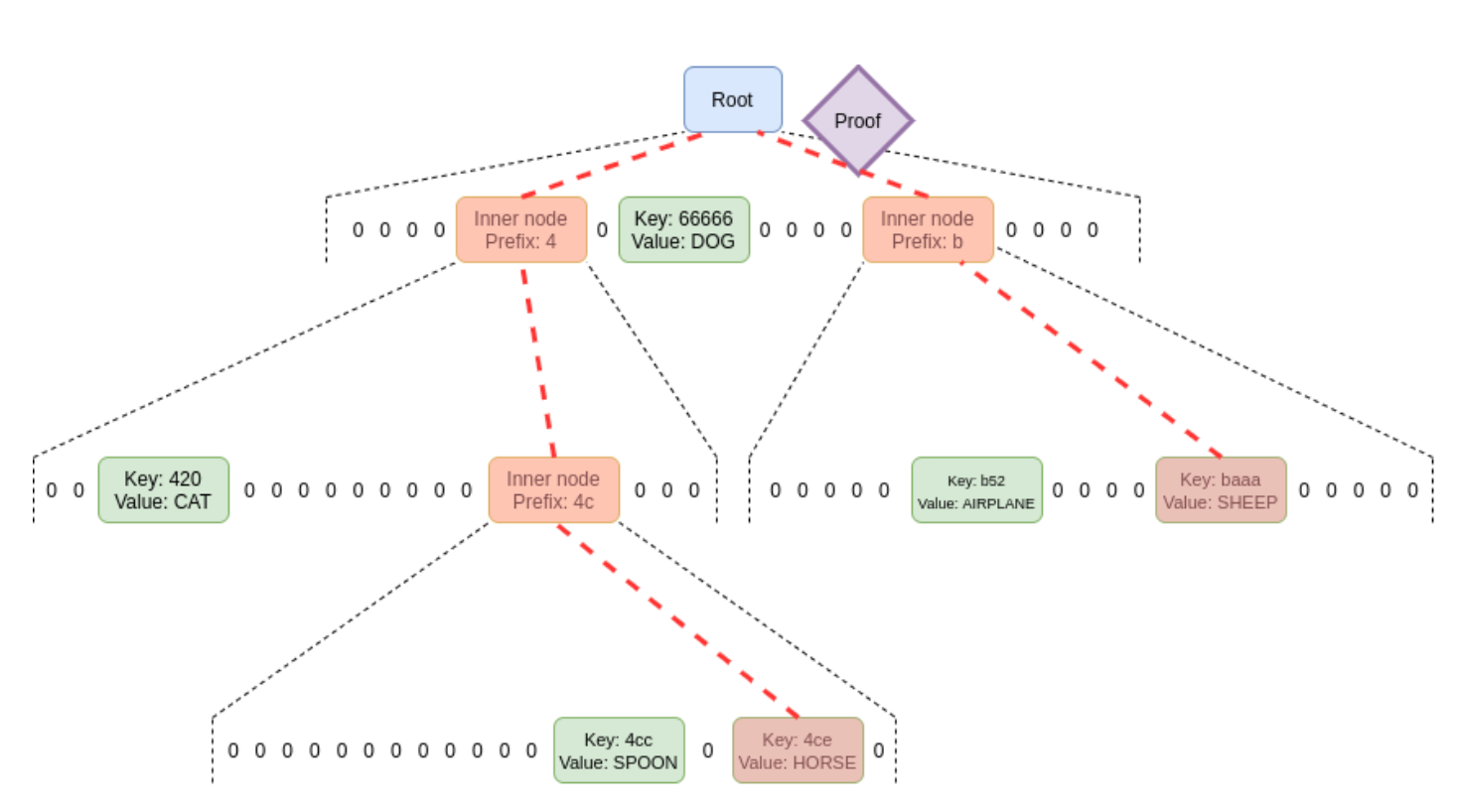
Let’s see how proofs are generated in an MPT: The proof needs to include the hash values of all the side nodes (or sister nodes) on the path from the root node to the target leaf node. Taking “4ce” as an example, the parts marked in red in the diagram below are the nodes that need to be included in the returned proof.
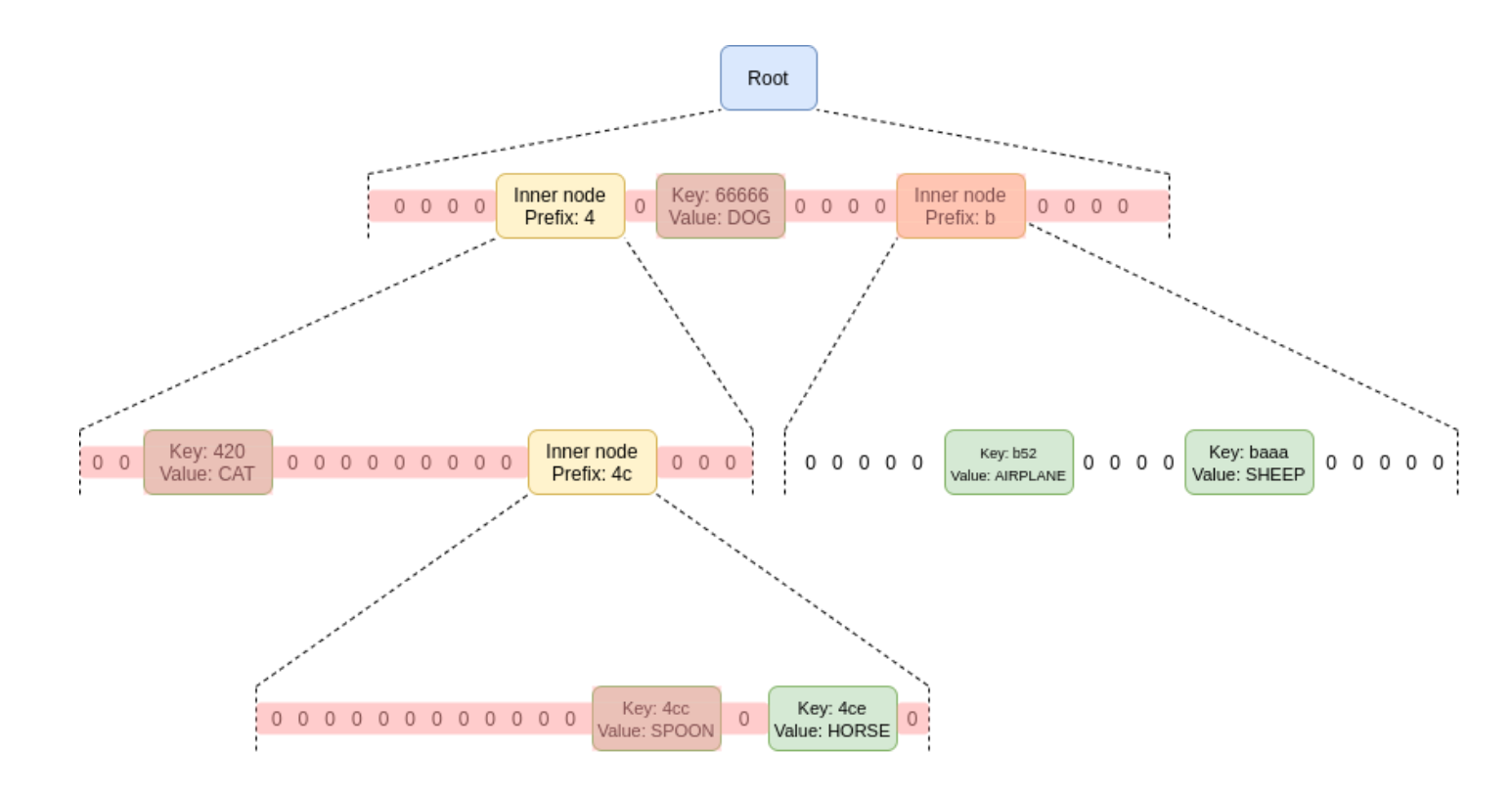
In Verkle trees, you do not need to provide sibling nodes; instead, you only need to provide the path along with some additional data as evidence.
So how to generate commitments for a VT? The hash function used for computation is not a conventional hash but uses vector commitments.
After replacing the hash function with a commitment generation algorithm from vector commitments, the so-called root hash is now a root commitment. If any node’s data is tampered with, it will ultimately affect the root commitment.
How to generate a proof? As shown in the diagram below, you only need to provide three sub-proofs, each of which can prove that a node on the path exists at a certain position within its parent node. The wider the width, the fewer the layers, and consequently, the fewer sub-proofs are required.
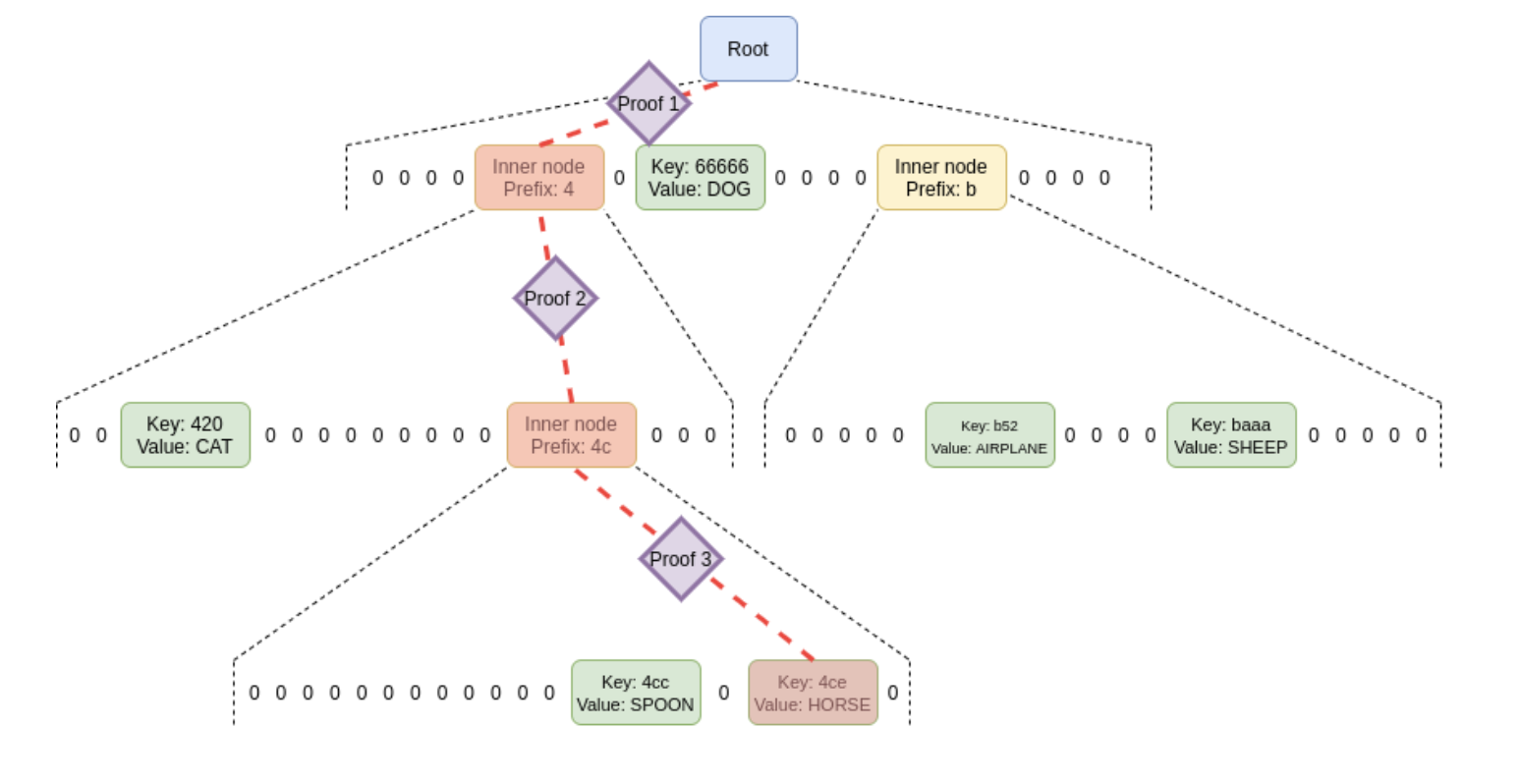
In practical implementations, polynomial commitments are utilized (which can be implemented simply and efficiently for vector commitments), allowing for a commitment to a polynomial. The two most user-friendly polynomial commitment schemes are “KZG commitments“ and “bulletproof-style polynomial commitments (the former has a commitment size of 48 bytes, while the latter is 32 bytes).
If you employ KZG commitments and proofs, the proof for each intermediate node is merely 96 bytes, which represents a space saving of nearly three times compared to a basic Merkle tree (assuming a width of 256).
The theoretical time complexity for operations on Merkle trees and Verkle trees is as follows:
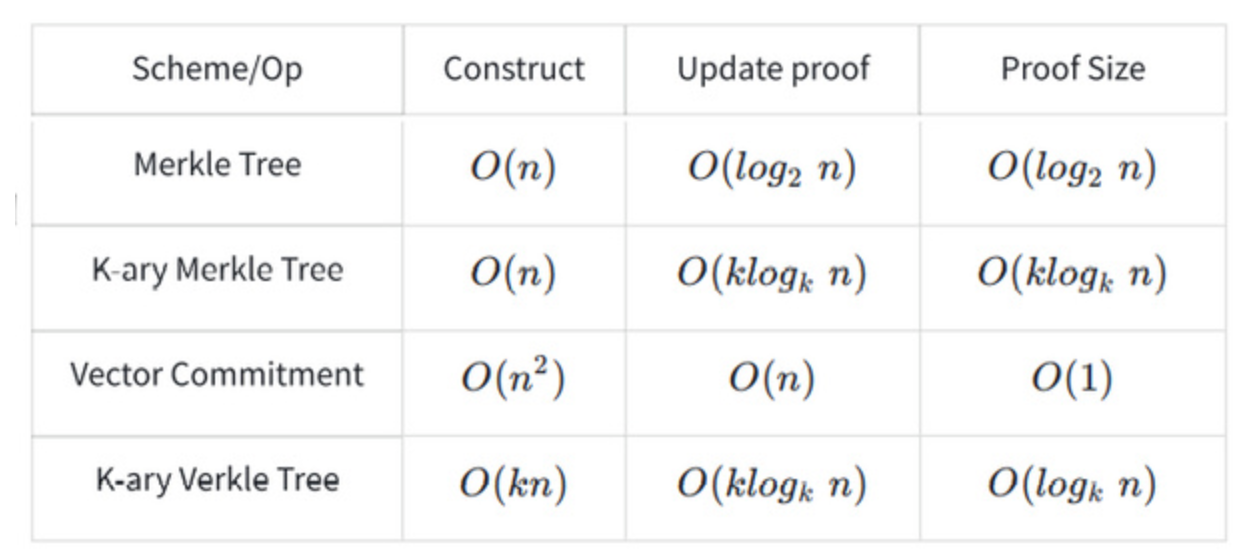
The Verkle proof scheme introduced so far is quite basic; in fact, there are further advanced optimization strategies available.
Optimization: Merging the Proofs
idea
Compared to generating a proof for each layer of commitments on a path, the characteristic of polynomial commitments can be utilized to achieve “proving the parent-child relationship between all commitments on the path with a proof of fixed size, which can include an unlimited number of elements.” To understand specifically how this is accomplished, it is necessary to introduce some mathematical knowledge for explanation. This article will involve some mathematical formulas but will not cover the cryptographic part of the proof in principle. For the specific method, please refer to scheme that implements multiproofs through random evaluation.
Mathematical derivation
First, let’s introduce some basic concepts about polynomials in mathematics: how do we perform polynomial reduction, also known as degree reduction of a polynomial?
Assuming that we know a polynomial $P(x)$ and its value $y_1$ at $x_1$,that is $P(x_1) = y_1$.
Now, consider a new polynomial $P(x) - y_1$, which has a value of zero at $( x = x_1 )$ , because $P(x_1) - y_1 = y_1 - y_1 = 0$.
Tererfore, The polynomial $P(x) - y_1$has a root at $x = x_1$ ,which means that $(x - x_1)$ is a factor of $P(x) - y_1$.
In other words, we can express it in the following form: $[ P(x) - y_1 = (x - x_1)Q(x) ]$
$Q(x)$ is another polynomial whose degree is one less than that of $P(x)$. This is beacuse $(x - x_1)$ is a first-degree factor, which reduces the total degree of the polynomial.
How to use KZG to prove a single value in a vector?
Take the KZG10 commitment as an example, for the polynomial $P(x)$, suppose its polynomial commitment is $[P(s)]_1$.
As previously explained, for the polynomial $P(x)$, if $P(z)=y$, then we have $Q(x)=(P(x)-y)/(x-z)$
Now, the prover can generate a proof that the polynomial $P(x)$ satisfies $P(z)=y$: compute $[Q(s)]_1$and send it to the verifier.
The verifier needs to verify $e([Q(s)]_1,[s-z]_2)=e([P(s)]_1-[y]_1,[1]_2)$.
How to use KZG to prove multiple values in a vector?
We can construct a proof to demonstrate multiple values in a vector as follows:
Suppose the verifier wants to prove that the polynomial $P(x)$ evaluates to $(z_0, z_1,\ldots,z_{k-1})$at points $(y_0, y_1,\ldots,y_{k-1})$.
Define two polynomials:
$I(x) : I(z_i) = y_i \quad \text{for each } i \in [0, k]$
$V(x) = \prod_{i=0}^{k-1}(x - x_i)$
In the same way, there exists a polynomial $Q(x)$ such that $Q(x) *V(x) = P(x) - I(x)$.
The prover computes commitments for the polynomials $P(x)$ and $Q(x)$, denoted as $[P(s)]_1$ and $[Q(s)]_1$, and sends them as proof to the verifier. The verifier can locally compute $[I(s)]_1$ and $[V(s)]_2$ and then verify that $e([Q(s)]_1,[V(s)]_2) = e([P(s)]_1 - [I(s)]_1, H)$.
By using this method, regardless of the number of data points in the same vector that need to be verified, only a proof of constant size is required.
Now let’s look at the Verkle Tree scheme without optimization from the perspective of the KZG commitment algorithm.
Suppose the verifier wants to prove a set of polynomials $f_0(x),f_1(x),\ldots,f_{m-1}(x)$ satisfy the following at $(z_0, z_1,\ldots,z_{m-1})$: $f_i(z_i)=y_i,\quad i \in [0, m-1]$
Using the construction method from the section “How to use KZG to prove a single value in a vector,” the verifier can construct commitments for the original and quotient polynomials for each polynomial $f_i(x)$, resulting in a total of $2*m$ KZG commitments. The verifier sends all these commitments as proof for verification.
However, as mentioned earlier, this approach requires generating multiple proofs, and the verifier also needs to perform multiple verification computations. We need to find a way to compress multiple commitment proofs.
Merging the Proofs
The verifier first randomly generates a series of random numbers$(r_0, r_1,\ldots,r_{m-1})$, and then combines the aforementioned quotient polynomials together: $g(x) = r_0q_0(z) + r_1q_1(z) + \ldots + r_{m-1}q_{m-1}(z)$.
Assume that $g(x)$ is a polynomial if and only if each quotient polynomial is indeed a polynomial. This is a reasonable assumption because the probability that the random numbers exactly cancel out all the coefficients of each term in all the quotient polynomials is very low.
The prover constructs a commitment $[g(s)]_1$ for $g(x)$ and sends it to the verifier. However, some commitments must also be constructed to convince the verifier that $[g(s)]_1$ is indeed a commitment to $g(x)$.
Let $g(x)=\sum_{i=0}^{m-1}r_i\frac{f_i(x)-y_i}{x-z_i}=\sum_{i=0}^{m-1}r_i\frac{f_i(x)}{x-z_i}-\sum_{i=0}^{m-1}r_i\frac{y_i}{x-z_i}$
Randomly select a value t, substitute it in, and get:$g(t)=\sum_{i=0}^{m-1}r_i\frac{f_i(t)-y_i}{t-z_i}=\sum_{i=0}^{m-1}r_i\frac{f_i(t)}{t-z_i}-\sum_{i=0}^{m-1}r_i\frac{y_i}{t-z_i}$
Next, define the following polynomial: $h(x)=\sum_{i=0}^{m-1}r_i\frac{f_i(x)}{t-z_i}$
The commitment to $h(x)$ can actually be expressed as $[h(s)]_1=\sum_{i=0}^{m-1}r_i \frac{C_i}{t-z_i}$ where $C_i$ is $[f_i(s)]1$. Because the polynomial $h(x)-g(x)$ at $x=t$ has: $h(t)-g(t)=\sum_{i=0}^{m-1}r_i\frac{y_i}{t-z_i}$, a proof can be constructed for $h(x)-g(x)$ where at $x=t$, $y=\sum_{i=0}^{m-1}r_i\frac{y_i}{t-z_i}$, with the corresponding quotient polynomial:$q(x)=(h(x)-g(x)-y)/(x-t)$.
The prover sends the proof $[q(s)]_1$ to the verifier for verification.
The evidence produced by this scheme consists of one commitment, two proofs, and one value, with constant data size. Eventually, after the proof merging optimization in the Verkle tree, the verifiable data object sent to the verifier includes the following:
- Constant size evidence
- The data of the leaves to be proven (key-value pairs)
- The commitment values of all nodes on the path from the leaf to the root (assuming a tree width of 256 with 2^32 nodes, then the average depth is 4, requiring only 3 commitment values)
Note that $x_i$ and $y_i$ do not need to be explicitly provided; they can all be computed.
performance
Regarding the proof merging scheme for Verkle trees, the specific size of the generated proof is as follows(The unit of the row is billion.):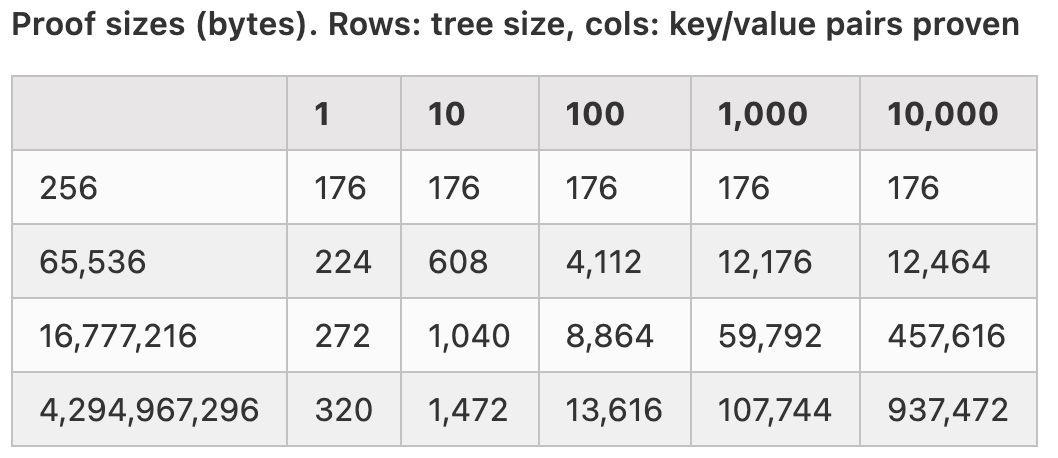
The above data assumes the usage of a tree of width 256, employing the KZG commitment scheme (with a commitment size of 48 bytes), and maximizes the utilization of the tree. In practice, for completely random distributions of information, the tree depth would increase by about 60%, and the size of each element would increase by 30 bytes. If the bulletproof scheme is used, then the commitment size would be 32 bytes.
Prover and verifier computation load
- Proof Generation: The cost of generating proofs by the prover is related to the tree’s width, but each atomic operation requires a relatively low computational cost, so Verkle trees with widths between 256 and 1024 perform well in terms of algorithms.
- Proof Verification: Vitalik has indicated that the verification algorithm is very fast and can typically be completed within 100ms, even when there are several thousand values to verify.
- When Updating Verkle Trees: Updating the tree requires recalculating all the intermediate commitment values along the path due to changes in values or structure. However, Vitalik mentioned that, thanks to some properties of the polynomial commitment algorithm, it is possible to design a method that precomputes alternative commitment values and stores them, thereby reducing the computational time cost during updates, which essentially trades space for time.
Conclusions
The following is the original words of vitalik blog, we added a paragraph at the end as a supplement。
Verkle trees are a powerful upgrade to Merkle proofs that allow for much smaller proof sizes. Instead of needing to provide all “sister nodes” at each level, the prover need only provide a single proof that proves all parent-child relationships between all commitments along the paths from each leaf node to the root. This allows proof sizes to decrease by a factor of ~6-8 compared to ideal Merkle trees, and by a factor of over 20-30 compared to the hexary Patricia trees that Ethereum uses today (!!).
They do require more complex cryptography to implement, but they present the opportunity for large gains to scalability. In the medium term, SNARKs can improve things further: we can either SNARK the already-efficient Verkle proof verifier to reduce witness size to near-zero, or switch back to SNARKed Merkle proofs if/when SNARKs get much better (eg. through GKR, or very-SNARK-friendly hash functions, or ASICs). Further down the line, the rise of quantum computing will force a change to STARKed Merkle proofs with hashes as it makes the linear homomorphisms that Verkle trees depend on insecure. But for now, they give us the same scaling gains that we would get with such more advanced technologies, and we already have all the tools that we need to implement them efficiently.
At present, many Ethereum clients have provided the implementation of the Verkle tree and related test networks. The community is still discussing the time when the Verkle Trees will be launched on the main network. It is likely to be implemented in a hard fork upgrade in 2024 or 2025. For detailed information about Verkle trees on Ethereum, see https://verkle.info/ 。
Reference
[1]. BRASSARD G, CHAUM D, CRÉPEAU C. Minimum disclosure proofs of knowledge[J]. Journal of computer and system sciences, 1988, 37(2): 156-189.
[2]. CATALANO D, FIORE D. Vector commitments and their applications[C]//Public-KeyCryptography–PKC 2013: 16th International Conference on Practice and Theory in Public- Key Cryptography, Nara, Japan, February 26–March 1, 2013. Proceedings 16. Springer, 2013: 55-72.
About
AntChain Open Labs
AntChain Open Labs is a research center initiated by AntChain and world leading computer scientists in the area of foundational trust technologies. It is dedicated to building a secure, transparent and reliable Web3 infrastructure driven by innovative research and aiming to advance transformative services.
Website:https://openlabs-intl.antdigital.com/home
ZAN
ZAN, powered by AntChain Open Labs, provides solutions for Web3, such as Smart Contract Review, KYT, KYC, Node Service, and more.
Website | Telegram | Discocd | Twitter | More
中文版
引言
2023年的最后一天,Vitalik在推特分享了2023年的以太坊路线图,对以太坊在2023年的进展做了总结。路线图中The Verge部分描述了如何更简单高效地验证区块链状态的以太坊技术。其中有个核心概念是Verkle树(Verkle Trees),那么什么是Verkle树,为什么需要Verkle树,它是怎么解决问题的?本篇文章的目标是在不涉及太多密码学和数学等知识的情况下为读者回答以上问题,帮助对以太坊有一定了解的读者快速了解Verkle树。
可验证查询技术
可验证查询技术在传统数据库领域研究广泛,主要用于解决外源数据库存在的信任问题。在许多场景下,数据的所有者可能不会选择自己存储数据,而是将自身的数据库需求委托给第三方,来为用户提供数据库服务(如云数据库),但由于第三方不总是可信的,因此其返回给用户的查询结果的可信性难以保证。 当前传统数据库的可验证查询方案主要有两种:基于ADS(Authenticated Data Structure)的方案和基于可验证计算的方案。
ADS 是广泛用于传统数据库的可验证查询技术,多数基于 Merkle 树或类似具有累加功能的结构构建。随着密码学工具的发展,许多研究者逐渐开始探索通过可验证计算技术来解决查询不可信的问题。一些基于零知识证明协议 SNARKs的可验证计算方案可间接用于支持外源数据库的可验证查询,这些方案可支持的查询类型丰富,且产生的验证信息较少,但其计算开销较大。
目前的以太坊利用Merkle树来实现可验证查询,而Verkle树技术也基于Merkle树技术。所以接下来先介绍Merkle树,以其为例子来帮助读者理解可验证查询的作用。
Merkle树
Merkle树的定义和特征
Merkle树是一个在密码学中常使用的树形结构,适用于解决数据完整性问题。 以下是一个典型的Merkle树结构,叶子节点为原数据或者其哈希值,每个非叶子节点为其子节点共同的哈希值。
Merkle树的重要特征有两点:
- 防止数据篡改 。Merkle 树构建时一般采用抗碰撞的哈希函数,使用这种哈希函数找到两个拥有相同哈希值的消息在计算上是几乎不可行的,从 Merkle 树的结构可以看到,对任意叶子结点中交易数据的修改,都将导致树根哈希值的变化 。
- 支持高效验证大量数据的完整性。验证者仅需保存 Merkle 树的树根哈希值,即可通过叶节点到树根路径上的兄弟节点来验证任意数据的完整性,而无需传输完整的数据,这些可以用来重构树根哈希的兄弟节点被称为 Merkle 路径(Merkle Path)
怎么构建Merkle证明?
一个普遍的可验证查询场景中有证明者(Prover)和验证者(Verifier),证明者需要生成证明并发送给验证者。对应到以太坊网络中,一个典型的应用场景是轻节点(只保存区块头的客户端)向全节点或者归档节点(拥有全部数据的客户端)查询交易数据,并获取Merkle证明在本地验证查询结果是否正确。
Merkle证明组成有以下3部份:
- 完整数据集的Merkle树根哈希
- 需要被证明完整性的数据块
- Merkle路径,即从叶节点到根节点路径上的所有兄弟节点的值。
其中Merkle树根哈希需要通过一种可信的手段提前发送给验证者,并让验证者信任这个值。以太坊中通过共识算法保证了区块数据的可信,Merkle树根哈希存在于区块头中。
下图是一个具体的例子,当证明者需要向验证者证明“4”是存在于这个数据集合中的数据块时,验证者持有可信的完整数据的Merkle树根哈希“1d25”,那么证明者只需提供所有标蓝的数据即可。假设集合中有n条数据,则最多只需$log_2(n)$次哈希计算即可验证任意数据段的正确性。
以太坊的轻节点只同步区块头,区块头中包含多个数据的Merkle树的根(状态树、交易树、收据树)。在轻节点向全节点查询树的某个叶节点数据时,全节点返回原数据以及对应的Merkle验证路径,轻节点就可以信任查询结果的正确性。
Merkle树的变种
在Merkle树的基础上,根据其它目的,可以把Merkle树和其它数据结构合并改造从而实现新的特性。针对各种不同的可验证查询场景,Merkle树可以被拓展到各种索引数据结构上,例如Merkle-B树(MBT)。为了高效完成插入、删除、查询等操作,以太坊团队提出了Merkle Patricia树(MPT)。
Merkle-B Tree
Merkle-B Tree主要用于处理可验证的范围查询。设 𝑓 为 MBT 的扇出(节点的子节点数量),在 B+ 树的基础上,MBT 的每个中间节点除了保存 𝑓 − 1 个索引关键字和 𝑓 个子节点的指针外,还会以摘要的形式保存所有子节点的哈希值。下图为MBT的叶子节点和中间节点的结构。
当需要证明某次范围查询返回的数据是符合范围,计算VO(Verification Object )的服务器需要先执行两次自上而下的搜索操作找到左右边界,并且返回这个边界的所有数据,以及构造到根哈希过程中所有需要的旁枝的哈希值。
这种数据结构的缺点是返回的VO只能证明查询结果在要求的查询范围内,但是不能证明返回结果是完整的。
Merkle Patricia Tree
如果简单地使用朴素的Merkle Tree来提供可验证查询,随着数据的插入或者删除,每次重新生成Merkle树根都需要大量的时间,同时还需要消耗存储维护额外的数据搜索树。Merkle Patricia Tree(MPT)结合了Redix Tree(压缩前缀树)和Merkle树,可以提供O(log(N))时间执行插入、删除、查询等操作。关于MPT的全部细节,读者可以另外查询专业的MPT技术文章,本文只介绍一些基础定义,并举例来帮助读者快速理解MPT。
以太坊的底层采用键值数据库来存储数据库,即数据以键值对的形式存储,MPT也被拆解为键值对进行存储。我们定义MPT的节点逻辑结构如下:
- 索引
- 路径
- 数据
其中“索引”为键值对的键,“路径”+“数据”构成键值对的值。索引实际存储的是Merkle树节点的哈希,路径对应前缀树中用来寻找目标节点的路径字符串,以太坊使用十六进制字符串作为路径字符串,所以MPT树的宽度为16。数据则为路径对应的目标数据。
以下为一个经过压缩前缀优化后的MPT例子,其中存储了如下键值对数据
1 | { |
以通过“395”寻找“duck”为例,从根哈希,经过hashA、hashC、hashD最终找到目标数据。
向量承诺
承诺(Commitment)[1]是一个密码学原语,是一种用于保证数据私密性和完整性的技术,被广泛应用于零知识证明、安全多方计算等场景中。一个基础的承诺方案分为2个阶段:承诺阶段和打开阶段。
- 承诺阶段,承诺者使用加密算法将消息绑定到一个承诺值上,并将此承诺值发送给接受者。在这一阶段,承诺具有隐藏性和绑定性。隐藏性是指在当前阶段,除承诺者之外没人知道被承诺的消息内容。绑定性是指承诺者一旦提交承诺,任何人都无法改变承诺的消息。
- 打开阶段,承诺者可以使用打开算法向接受者证明,发送给他的承诺值是对原消息的一个有效承诺。承诺具有正确性,即如果承诺者和接受者都正确履行协议, 接受者在打开阶段会确信他接收到的承诺值是对原消息的有效承诺。
向量承诺(Vector Commitment )是一种由 Catalano 等人提出的特殊承诺方案[2],它允许承诺者对一组有序的消息 𝑚 = ⟨𝑚1 , 𝑚2 , …, 𝑚𝑞 ⟩ 进行承诺,并在任意的指定位置打开,以证明消息 𝑚𝑖 是第 i 个被承诺的消息。在向量承诺中,绑定性意味着任何人都无法在同一个位置打开得到不同的消息。一个向量承诺算法通常由以下算法组成:
- $Gen(1^λ,q)→pp$,密钥生成算法,在输入安全参数 λ 和向量长度 𝑞 后,输 出公共参数 𝑝𝑝;
- $Commit(pp,
- $Open(pp,i,m_i,C,aux)→π$,证明生成算法,输入公共参数 𝑝𝑝 和相关信 息,当且仅当 𝑚𝑖 是消息向量中的第 𝑖 个消息时,该算法通过承诺 𝐶 和辅助 信息 𝑎𝑢𝑥 生成一个证明 𝜋;
- $Verify(pp,C,i,m,π)→{accept \ or\ reject}$,验证算法,输入公共参数 𝑝𝑝、承诺 𝐶、消息 𝑚 和位置 𝑖,以及证明 𝜋,当且仅当消息 𝑚 是原向量中的第 i 个消 息时,𝜋 通过验证,输出 accept,否则输出 reject。
Verkle Tree
Verkle树的定义和特征
定义:Verkle Trees = Vector Commitments + Merkle Trees。
说明:Vitalik有一篇专门介绍Verkle树的博客,本文在其基础上增加一些对数学和背景知识的补充,下文部分数据和图例来自其博客Verkle trees。
Verkle树(VT)的特征是提供比Merkle 树更小的证明。对于十亿级别的数据,Merkle树生成的证明大概是1KB,而Verkle 树生成的证明会不到150B。这有利于实现“stateless clients ”。
Verkle 树的结构和MPT很类似,以下是一个例子。其节点要么是 (i) 空的,要么是 (ii) 一个叶子节点,包含一个键和对应的值,或者是 (iii) 一个中间节点,拥有固定数量个子节点(这个数量也即是树的 “宽度”)。
VT和MPT的区别是,MPT的宽度(或者扇出,指树中一个节点的子节点数量)如果越大,其效率越低,因为宽度越大意味着兄弟节点越多,可能会导致更新MPT的时间变长和生成的证明大小变大;相反的,VT的宽度越宽,其生成的证明就越小。唯一的限制是如果宽度过高,生成证明的时间会比较长。以太坊关于VT的设计提案中就建议宽度为256,远超MPT目前的16。后文会对以上特征做解释。
Verkle树的承诺和证明
先看看MPT是怎么生成证明的:证明中需要包含所有从根节点到目标叶子节点路径上的所有旁路节点(兄弟节点)的哈希值。以4ce为例,下图中画红的部分即需要返回所包含的节点。
而在Verkle树上,你不需要提供兄弟节点;相反,你只需要提供路径,再加一些额外的数据作为证据。
那么如何为VT生成承诺呢?这时候用来计算的哈希函数不是常规的哈希,而是使用向量承诺。
将哈希函数替换为向量承诺的承诺生成算法之后,那么所谓的根哈希就是根承诺了。如果每一个节点的数据发生篡改,最终都会影响到根承诺。
如何生成证明?如下图所示,只需要提供三个子证明,每个子证明可以证明路径上的节点是存在于父节点的某个位置上。如果宽度越大,层数越少,需要的子证明数量也就越少了。
实际实现中,会使用多项式承诺(可以简单高效地实现向量承诺),其允许对一个多项式进行承诺。最容易使用的两种多项式承诺方案是 “KZG 承诺” 和 “bulletproof 类型的承诺”(在两种方案中,一个承诺都是单个 32 ~ 48 字节的椭圆曲线点)。
如果你使用 KZG 承诺和证据,每个中间节点的证据只有 96 字节,比起简单Merkle树有接近 3 倍的空间节约(假设宽度为 256)。
Merkle树和Verkle树的操作理论时间代价如下:
目前为止介绍的Verkle证明方案还比较基础,实际上还有更进一步的优化方案。
优化:合并证明
思路
相比于为路径的每一层承诺生成一个证明,可以使用多项式承诺的特征来实现“用一个固定大小的证明证明路径上所有承诺之间的父子关系,并且可以包含无限量的元素”。如果想要更具体地了解是做到这一点,就必须引入一些数学知识来做说明了,本文的讲解会涉及一些数学公式,但不会引入密码学部分的原理证明。具体方法请参考scheme that implements multiproofs through random evaluation。
数学证明
首先我们来介绍一下数学中关于多项式的基础概念:如何对一个多项式进行降阶?
如果我们知道一个多项式$P(x)$ 和它在某一点$x_1$的值为$y_1$,那么 $P(x_1) = y_1$。
现在,考虑一个新的多项式$P(x) - y_1$,它在$( x = x_1 )$ 处的值是零,因为 $P(x_1) - y_1 = y_1 - y_1 = 0$。
因此,$P(x) - y_1$这个多项式在 $x = x_1$ 处有一个根,即 $(x - x_1)$ 是$P(x) - y_1$的一个因子。
换句话说,我们可以写出这样的形式:$[ P(x) - y_1 = (x - x_1)Q(x) ]$
其中$Q(x)$是另一个多项式,其次数比$P(x)$少一。这是因为 $(x - x_1)$ 是一个一阶因子,它降低了多项式的总次数。
如何使用KZG来证明向量中的单个值?
以KZG10承诺为例,对于多项式$P(x)$,设其多项式承诺为$[P(s)]_1$。
前文已经说明,对于多项式$P(x)$,如果有$P(z)=y$,则有$Q(x)=(P(x)-y)/(x-z)$。
现在证明者可以为多项式$P(x)$满足$P(z)=y$生成一个证明:计算$[Q(s)]_1$并发送给验证者。
验证者需要验证$e([Q(s)]_1,[s-z]_2)=e([P(s)]_1-[y]_1,[1]_2)$。
如何使用KZG来证明向量中的多个值?
我们可以构造一个证明来证明向量中的多个值,具体做法如下:
设验证者想证明多项式$P(x)$,在$(z_0, z_1,\ldots,z_{k-1})$上的值为$(y_0, y_1,\ldots,y_{k-1})$。
定义两个多项式:
$I(x) : I(z_i) = y_i \quad \text{对于所有} i \in [0, k]$
$V(x) = \prod_{i=0}^{k-1}(x - x_i)$
那么同理,存在多项式$Q(x)$,满足$Q(x) *V(x) = P(x) - I(x)$。
证明者计算对多项式$P(x)$、$Q(x)$的承诺$[P(s)]_1$、$[Q(s)]_1$作为证明发送给验证者,验证者可以在本地计算$[I(s)]_1$、$[V(s)]_2$,验证者验证$e([Q(s)]_1,[V(s)]_2) = e([P(s)]_1 - [I(s)]_1, H)$。
通过这种方式,不管想要验证同一向量中的数据数量有多少个,都只需要恒定大小的证明即可。
现在我们从KZG承诺算法的角度来看没有优化前的Verkle Tree方案
设验证者想证明多项式集合 $f_0(x),f_1(x),\ldots,f_{m-1}(x)$,在 $(z_0, z_1,\ldots,z_{m-1})$ 上满足:
$f_i(z_i)=y_i,\quad i \in [0, m-1]$
通过“如何使用KZG来证明向量中的单个值”部分的构造方式,验证可以为每个多项式$f_i(x)$构造原多项式和商多项式的承诺,总计 $2*m$ 个KZG承诺。将这么多承诺作为证明发送给验证者进行验证。
但是正如前面说到的,这样需要生成多个证明,验证者也需要多次验证计算。我们需要想办法把多个承诺证明进行压缩。
合并证明的优化方案
验证者先随机生成一系列随机数 $(r_0, r_1,\ldots,r_{m-1})$,然后把上述商多项式组合在一起:
$g(x) = r_0q_0(z) + r_1q_1(z) + \ldots + r_{m-1}q_{m-1}(z)$
假设当且仅当每个商多项式确实为多项式时,$g(x)$ 才是一个多项式。这是一个合理的假设,因为随机数恰好把所有商多项式各次的系数全部抵消的概率很低。
证明者会对 $g(x)$ 构造承诺 $[g(s)]_1$ 并发送给验证者。但是还需要构造一些承诺让验证者相信 $[g(s)]_1$ 是 $g(x)$ 的承诺。
令 $g(x)=\sum_{i=0}^{m-1}r_i\frac{f_i(x)-y_i}{x-z_i}=\sum_{i=0}^{m-1}r_i\frac{f_i(x)}{x-z_i}-\sum_{i=0}^{m-1}r_i\frac{y_i}{x-z_i}$
随机选取t值,代入得:
$g(t)=\sum_{i=0}^{m-1}r_i\frac{f_i(t)-y_i}{t-z_i}=\sum_{i=0}^{m-1}r_i\frac{f_i(t)}{t-z_i}-\sum_{i=0}^{m-1}r_i\frac{y_i}{t-z_i}$
接着定义如下多项式:
$h(x)=\sum_{i=0}^{m-1}r_i\frac{f_i(x)}{t-z_i}$
$h(x)$ 承诺的计算方式其实可以表示为
$[h(s)]_1=\sum_{i=0}^{m-1}r_i\frac{C_i}{t-z_i}$,$C_i$ 为 $[f_i(s)]1$
因为多项式 $h(x)-g(x)$ 在 $x=t$ 时有:$h(t)-g(t)=\sum_{i=0}^{m-1}r_i\frac{y_i}{t-z_i}$,
所以可以为 $h(x)-g(x)$ 构造其在 $x=t$ 时 $y=\sum_{i=0}^{m-1}r_i\frac{y_i}{t-z_i}$的证明,对应的商多项式为:
$$q(x)=(h(x)-g(x)-y)/(x-t)$$将证明 $[q(s)]_1$ 发送给验证者进行验证。
该方案生成的的证据为一个承诺、两个证明和一个值,数据大小恒定。
最终,在Verkle树合并证明优化后,发送给验证者的可验证数据对象包含以下内容:
恒定大小的证据
想证明的叶子节点数据(键值对)
叶子节点到根节点路径上的所有节点的承诺值(假设树宽度为256,有2^32个节点,那么平均深度为4,只需提供3个承诺值)
注意,$x_i$和$y_i$不需要显式提供,都可以被计算出来。
性能
就Verkle树的合并证明方案而言,其生成的证明具体大小如下:
行为树的大小,单位为billion;列为查询的键值对数量。
以上数据假设使用树宽度为256,使用KZG承诺方案(一个承诺大小为48字节),树的利用率最大化。实际情况,如果是完全随机分布的信息,树深度增加约60%,每个元素增加30字节大小。若使用bulletproof方案,则承诺大小为32字节。
证明者和验证者的计算开销
生成证明:证明者生成证明的开销和树的宽度有关,但是每个单元操作需要的计算代价比较小,所以Verkle树的宽度在256至1024之间的算法表现不错。
验证证明:vitalik表示验证算法很快,基本可以在100ms内完成,即使想要验证的数值有几千个。
当更新Verkle树时:更新树的时候,因为值或者结构发生了变化,通常需要重新计算路径上所有的中间承诺值。但是vitalik表示,根据多项式承诺算法的一些性质,可以设计预先计算备用的承诺值并存储下来,从而减少更新时的计算时间开销,即用空间换取时间。
总结
对比Merkle树,Verkle树是非常强大的升级,它使我们可以做出小得多的证据。运用Verkle树之后,证明者不再需要提供路径上所以层级的所有 “姐妹节点”,只需为从根节点到目标叶子节点路径上的所有承诺值之间的父子关系提供一个证据。只此一点,就可以让证据的大小缩小约 6 ~ 8 倍(对比理想的Merkle树),若是对比以太坊当前所用的MPT,可缩小超过 20 ~ 30 倍。
Verkle树需要更复杂的密码学来实现,但它有机会给可扩展性带来巨大收益。从中期来看,SNARK 可以提升更多:我们既可以 SNARK 化已经很有效率的 Verkle证据验证者,把见证数据的大小降低到近于零;或者切换回 SNARK 化的Merkle证据,只要 SNARK 可以变得更好(例如,通过 GKR、或者 SNARK 极度友好型的哈希函数,或者 ASIC)。更进一步地说,量子计算的兴起会让Verkle树所依赖的线性同态属性变得不安全,所以我们必须转向 SNARK 化的Merkle证据。但从目前来看,Verkle树给了我们同样的可扩展性收益(比起其他更高级的技术),而我们已经具备了高效实现Verkle树所需的所有工具。
目前许多以太坊客户端已经提供Verkle树的实现并有相关测试网,关于Verkle树上线主网的时间社区仍旧在讨论,有较大可能会在2024或者2025的某次硬分叉升级中实现。以太坊上关于Verkle树的详细信息见https://verkle.info/ 。
参考
[1]. BRASSARD G, CHAUM D, CRÉPEAU C. Minimum disclosure proofs of knowledge[J]. Journal of computer and system sciences, 1988, 37(2): 156-189.
[2]. CATALANO D, FIORE D. Vector commitments and their applications[C]//Public-KeyCryptography–PKC 2013: 16th International Conference on Practice and Theory in Public- Key Cryptography, Nara, Japan, February 26–March 1, 2013. Proceedings 16. Springer, 2013: 55-72.
关于我们 About Us
AntChain Open Labs
AntChain Open Labs is a research center initiated by AntChain and world leading computer scientists in the area of foundational trust technologies. It is dedicated to building a secure, transparent and reliable Web3 infrastructure driven by innovative research and aiming to advance transformative services.
Website:https://openlabs-intl.antdigital.com/home
ZAN
ZAN是蚂蚁数科旗下新科技品牌。依托AntChain Open Labs的TrustBase开源开放技术体系,拥有Web3领域独特的优势和创新能力,为Web3社区提供可靠、高性价比的区块链应用开发技术产品和服务。
凭借AntChain Open Labs的技术支持,ZAN为企业和开发者提供了全面的技术产品和服务,其中包括智能合约审计(ZAN Smart Contract Review)、身份验证eKYC(ZAN Identity)、交易风控技术(ZAN Know Your Transaction)以及节点服务(ZAN Node Service)等。
通过ZAN的一站式解决方案,用户可以享受到全方位的Web3技术支持。
ZAN Website:https://zan.top/home
Website | Telegram | Discocd | Twitter | More